[读书笔记]《西瓜书》第五章 神经网络 补充五
![[读书笔记]《西瓜书》第五章 神经网络 补充五](/images/machine-learning_huda146d3825fc6d502e05b38609bff098_23368_900x500_fit_q75_box.jpg)
第五章 神经网络 补充五
神经网络是现在主流的机器学习处理问题的手段,因此需要更加细致的去学习,所以这里自己搜集了一些补充知识点,而且感觉应该需要拆分成几个小章节进行论述,因此这里会使用副标题
过拟合
PS:为了想把这一章节写好,又回头刷了一遍林轩田老师的机器学习基石的视频,同时把《DEEP LEARNING》中的第七章又好好看了一遍。对于严谨的数学证明可能并不能完全的掌握,但是基本的思想和推理逻辑大致是明白了。这篇博文的内容自己组织的并不是很好或者存在论述错误,但是我会尽可能的把自己想阐述内容都阐述清楚。
一个问题
OK,所有的论述都从一个核心问题展开 —- 神经网络模型一定会过拟合吗?
首先把这个问题的由来讲述一下:
- 在自己查看网上的一些博文的时候,发现大部分的文章都是着重在介绍神经网络模型过拟合的处理的方法的总结;
- 在论文和书籍中,经常会以学术的角度告诉读者,为了解决模型的优化然后采取了什么样的措施;
- 奉为经典的吴恩达老师和李宏毅老师的视频中,多次提到了神经网络模型发展历史中经过严谨的数学证明了,其可以拟合任意的函数。
有了以上三个基本的知识前提之后,自己心里突然涌现了这个问题。当然这个问题看似很无聊,因为答案看似是很浅显明了的,应该很多人都会说:“不”,很多书本上也提到了神经网络欠拟合的问题和现象。但是在我看来这个问题的答案却是:“一定会”。
So,为什么我会这么说?
其实在这个问题提出来的时候,隐含掉了前提条件:“在神经网络中的神经元足够多,并且迭代优化过程足够的好的情况下”。这种情况下神经网络一定会过拟合。因为在这个前提下,无论是论文还是书中都明确的说明了,神经网络模型能够拟合任意结构的函数,就说明模型本身的容量能够完全模拟出来在训练神经网络模型给出的数据集的全部性态构成的函数结构,那么当我们使用优化算法进行迭代优化的过程中,在不考虑时间和算力的情况下,我们是肯定能够在该函数模型的结构下找到其全局最小值点的,那么必然神经网络一定是过拟合的。
PS:这里使用了诡辩的强词夺理的方式,其目的是为了让自己能够更好地记住神经网络的特性,而并非诡辩。属于自己的学习方式的一种。
也许你并不认可我的这种说法,但也像是上面👆我说的那样,这只是为了满足我自己的学习需求。不过反过来再思考一个问题:“为什么神经网络会出现欠拟合?”。相比上面那个问题,这个问题的答案反而显而易见了,相信没有太多的争议,其主要的原因就是两点:
PS: 也是个人总结的,如果有问题请留言讨论哈
- 第一类是因为在神经网络训练过程中,我们采用了的网络结构不能够覆盖数据集中我们想要的全部特征导致出现了欠拟合;
- 第二类是因为在网络结构能够满足需求的情况下,因为梯度下降优化算法在迭代过程中,没有达到理论上较好地次数,导致出现了欠拟合。
总结一下,换成大白话是不是就是:我们无法确定需要多少个神经元来处理当前的数据集,并且也无法知道在训练过程中,究竟迭代多少次是最优解。所以再回过头来看上面那个问题的解答,多多少少就会get到我的想法了~
那么,接下来就是结合上面我自己所阐述的答案的前提下,该如何解决神经网络的过拟合的问题呢?
解决方案
无论是网络上还是各类书籍中都林林总总的给了很多的优化方法,但是要说总结的比较全的当然是《DEEP LEARNING》(花书)了,但是与之对应的就是花书中的描述都太过学术化,并且中文翻译没有结合语境导致读起来还是挺晦涩的(PS:这里算是吐槽一下,但是我自己也没有太大的能力把花书的英文原版啃完~),于是结合花书和网上的资料,自己把现在各类框架中常用的,或者说落地中比较好用的几个阐述罗列一下,并不会涉及花书中的各种公式证明之类的,主要是一些重要的知识点,为了自己以后的查找方便~
正则化:在机器学习中,许多策略被显式地设计来减少测试误差(可能会以增大训练误差为代价)的策略,这些策略统称为正则化。
首先特别需要声明的就是这些方法在花书中统称为正则化,所以我们需要特别声明的就是正则化的确切定义。上面👆给出的就是花书中给出的正则化的定义,虽然不明白这个定义也不影响学习过拟合优化的处理方法,但是我觉得还是应该深记于心。
$L^2$正则化和$L^1$正则化
因为不需要把具体的证明步骤进行阐述一遍,所以可以大幅的缩减篇幅,就将两者结合到一起进行梳理了。
概念
这两种在花书中都被称为参数范数惩罚,即其策略为通过对目标函数 $J$ 添加一个参数范数惩罚 $\Omega(\boldsymbol{\theta})$ ,限制模型(如神经网络、线性回归或逻辑回归)的学习能力。
形式
$$\hat{J}(\boldsymbol{\theta};X,\boldsymbol{y}) = J(\boldsymbol{\theta};X,\boldsymbol{y}) + \alpha\Omega(\boldsymbol{\theta})$$
其中 $\alpha \in [0, \infty)$ 是权衡范数惩罚项 $\Omega$ 和标准目标函数 $J(X;\boldsymbol{\theta})$ 相对贡献的超参数。
PS:这里额外插一个问题:为什么只对权重进行惩罚而不对偏置做惩罚?
相信很多人看花书的时候会略过这个问题,但是我觉得这地方还是值得记忆一下的。花书也给了明确的答案:因为精确拟合偏置所需的数据通常比拟合权重少得多。每个权重会指定两个变量如何相互作用。我们需要在各种条件下观察这两个变量才能良好地拟合权重。而每个偏置控制一个单边量。这意味着我们不对齐进行正则化也不会导致太大的方差。另外,正则化偏置参数可能会导致明显的欠拟合。
接下来因为之前在线性模型补充中整理过Lasso和Ridge在损失函数中的作用了,对比之下两者并没有太大的区别,因此将部分内容粘贴在此。
首先要明确的一个问题是标准线性回归的公式最终求解的公式为 $\boldsymbol{w}=(X^{T}X)^{-1}X^{T}\boldsymbol{y}$ 中可以看出在计算回归系数的时候我们需要计算矩阵 $X^{T}X$ 的逆,但是如果该矩阵是个奇异矩阵,则无法对其进行求解。
那么什么情况下该矩阵会有奇异性呢?
-
$X$ 本身存在线性相关关系(多重共线性),即非满秩矩阵。
如果数据的特征中存在两个相关的变量,即使并不是完全线性相关,但是也会造成矩阵求逆的时候造成求解不稳定。
-
当数据特征比数据量还要多的时候,这时候矩阵是一个矮胖型的矩阵,也是非满秩的矩阵。
Lasso和Ridge在损失函数
二者的共同目的都是为了将回归系数 $\boldsymbol{w}$ 收缩到一定的区域内,防止模型的过拟合
Lasso
Lasso的主要思想是构造一个一阶惩罚函数,来得到一个防止过拟合的模型。
本质为:
以两个变量为例,标准线性回归的loss function还是可以用二维平面的等值线表示,Lasso的约束条件可以用方形表示,如下图:
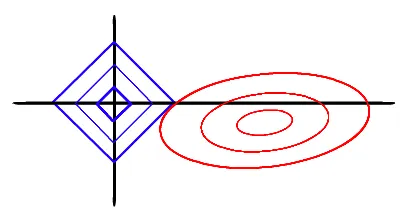
当方形的顶点与抛物面相交时,其切点在坐标轴上的概率更大,因此其对应的权重变为0
其本身特点有:
- Lasso 对于异常值不敏感
- Lasso 可以将权重较小的值,置为0,因此可以用作特征选择
- Lasso 可能存在多个最优解
Ridge
Ridge的主要思想是构造一个二阶惩罚函数,来得到一个防止过拟合的模型。
本质为:
以两个变量为例, 标准线性回归的loss function还是可以用二维平面的等值线表示。而Ridge限制条件相当于在二维平面的一个圆。如下图:
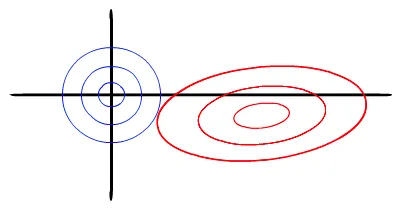
这个时候等值线与圆相切的点便是在约束条件下的最优点,但通常情况下,其切点在坐标轴上的概率较小,因此其对应的权重很难变为0
其本身的特点有:
- Ridge 在计算过程中十分方便
- Ridge 一定只有一条最好的预测线
- Ridge 对于异常值要比 Lasso 敏感一点
对比
这里详细的内容参见 知乎答案 L1正则与L2正则的特点是什么,各有什么优势?
这里摘抄两个图粘贴在此,以作为方便记忆上面的Lasso和Ridge各自的特点
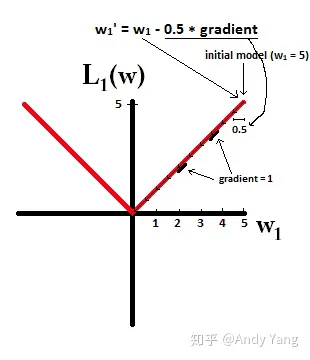
在梯度更新时,不管 L1 的大小是多少(只要不是0)梯度都是1或者-1,所以每次更新时,它都是稳步向0前进。
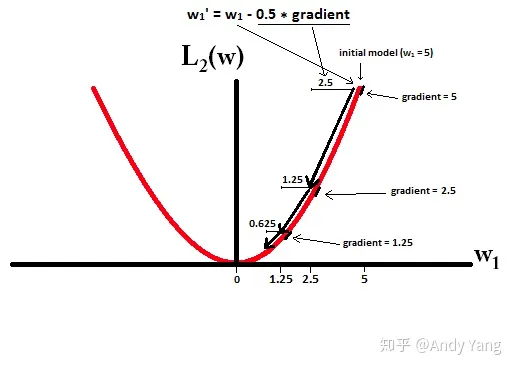
而看 L2 的话,就会发现它的梯度会越靠近0,就变得越小。
也就是说加了 L1 正则的话基本上经过一定步数后很可能变为0,而 L2 几乎不可能,因为在值小的时候其梯度也会变小。于是也就造成了 L1 输出稀疏的特性。
更好的数据
最通俗直白的观点,即让机器学习模型泛化得更好的最好办法是使用更多的的数据进行训练。
PS:这里我觉得可能就是现在为啥说深度学习模型十分优越的根本点,就是数据量大。但是这里我不得不吹一下台大的李宏毅和林轩田两位老师的课程,两位老师在课程里说的十分的明白,即神经网络模型之所以效果好,并非是因为对比传统机器学习模型使用的数据量大,而是在进行相同的作业情况下,神经网络模型会使用module ensemble的方式来达到效果,也就是说神经网络能够解决的问题用传统机器学习模型应该是也可以解决的,但因为module的不共享,params的不同享,导致可能会需要更大的数据量和参数量,所以神经网络模型才在现在如此火爆,是因为她能够解决的问题反而需要更少的数据量和参数。
“更好的数据”其实本质上是因为,我们为了求得模型在真实环境中的泛化误差最小化,需要的是模型学到的是基本的通用的特征,而非样本集特定的特征,但是往往因为我们采集到的数据集大部分都是一些inliner的样本,导致我们的模型可能会将inliner的部分样本特征当做真实数据特征学到了,所以为了避免这一情况,我们需要一些outliner来纠正这一现象,因此好的数据集是能够让模型看见尽可能多类型的outliner,从而得到更好的结果。
常用的方式:
- 从源头获取更多的数据
- 根据当前样本集分布产生更多的样本集
- 数据增强
例如在CV领域中数据增强就发挥了举足轻重的作用~
提前终止
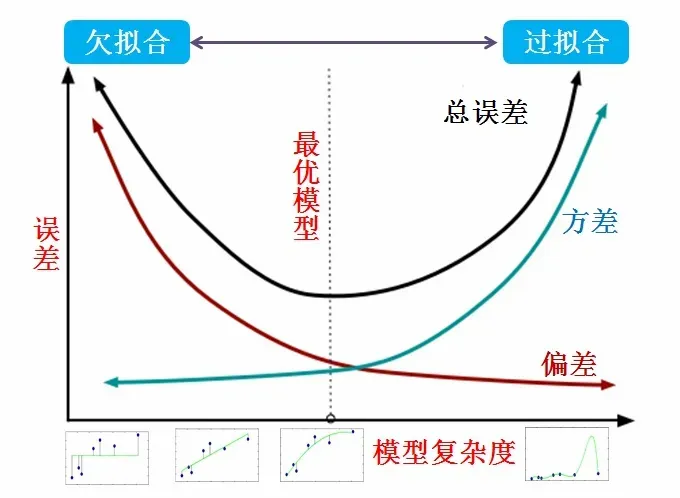
在神经网络模型训练过程中,几乎一定会出现的现象就是随着时间的推移(即训练迭代次数的逐渐增涨)训练误差会逐渐降低,但验证集的误差会再次上升。但这其实是一件好事,即意味着我们只要返回是验证集误差最低时的网络结构中的参数配置,就可以获得验证集误差更低的模型。
在每次验证集误差有所改善后,我们存储当前网络结构中参数的设置。当训练算法终止时,返回存储的参数,值得注意的是,这些参数不是一定是当前网络模型中的最新的参数,并且当验证集上的误差在事先指定的循环次数内没有进一步改善时,算法就会终止。
这即是提前终止(early stopping)的概念
在知道定义之后,花书中这里有个关键的论证点,即:提前终止为何具有正则化效果?
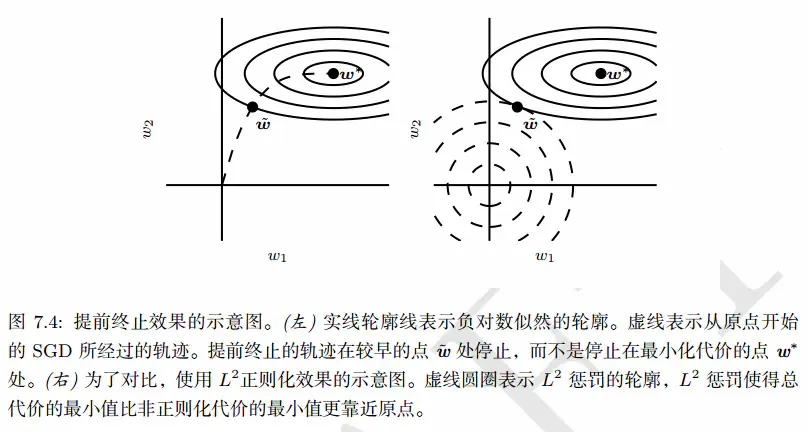
PS:对应的数学证明在花书 P 155页,这里这个结论记住其实就可以了,即我们不需要在使用正则化的同时使用早停的方式来防止模型的过拟合,因为二者的效果本质上是重复了,所以无需叠加。
集成方法
这里其实就是借助西瓜书中介绍的集成学习的方法来实现对神经网络模型的泛化误差降低的方式。其中尤为特别需要记忆的就是Bagging(bootstrap aggregating)方式。
Bagging
Bagging是通过结合几个模型降低泛化误差的技术,其主要想法是分别训练几个不同的模型,然后让所有模型表决测试样例的输出。其中常规的策略是模型平均(model averaging),其奏效的原因是不同的模型通常不会再测试集上产生完全相同的误差。
PS:具体的Bagging采样方式和模型在记录西瓜书第八章笔记的时候再细谈~
Boosting
这里在花书中对Boosting技术的介绍是构建比单个模型容量跟高的集成模型。通过向集成逐步添加神经网络,Boosting已经被应用于构建神经网络的集成。通过逐渐增加神经网络的隐藏单元,Boosting也可以将单个神经网络解释为一个集成。
PS:这里就跟之前提到的李毅宏老师在课程中说到一样了,即神经网络其实是module层面的ensemble方法。
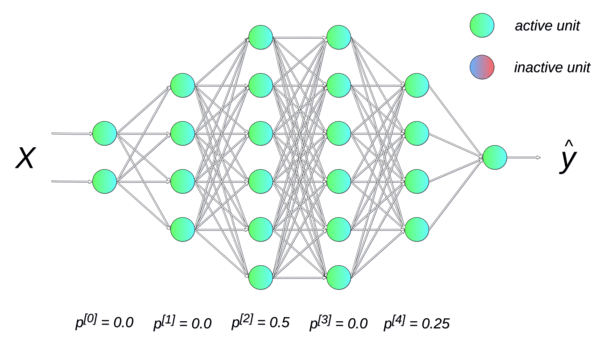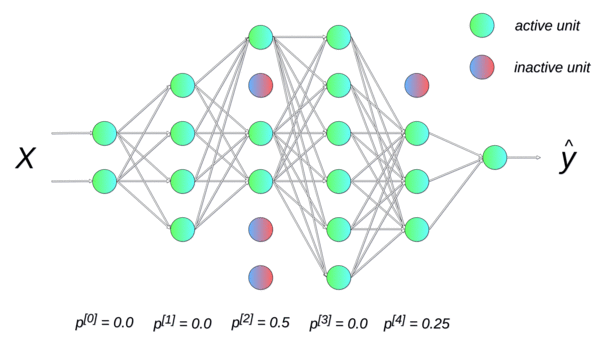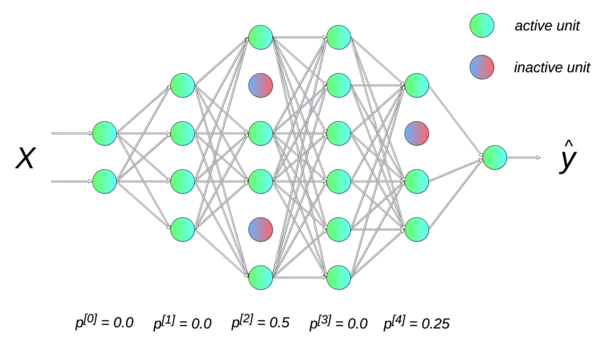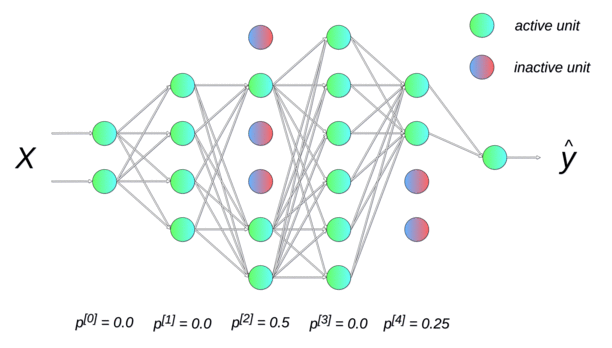
Dropout(随机失活)
Dropout提供了正则化一大类模型的方法,计算方便但功能强大。在第一种近似下,Dropout可以被认为是集成大量深度神经网络的实用Bagging方法。
Dropout提供了一种廉价的Bagging集成近似,能够训练和评估指数级数量的神经网络模型。
Dropout训练和Bagging训练不太一样,在Bagging下,所有模型都是独立的。在Dropout的情况下,所有模型共享参数,其中每个模型继承父神经网络参数的不同子集,参数共享使得在有限可用的内存下表示指数级数量的模型变得可能。在Bagging的情况下,每一个模型在其相应训练集上训练到收敛。在Dropout的情况下,通常大部分模型都没有显式地被训练,因为通常父神经网络会很大,以至于到宇宙毁灭都不可能采样完所有的子网络。取而代之的是,在单个步骤中我们训练一小部分的子网络,参数共享会使得剩余的子网络也能有好的参数设定。
上面👆这些内容是取自花书中个人觉得比较重要的部分,然后记录在此,后面的内容暂时自己理解也不是很深刻,等回头更新花书学习笔记的时候在精读一下吧。
此外经过我查了一下文章和书籍,发现目前神经网络正则化处理方式在大规模实施过程中最常用的就是随机失活这种方式了。
总结
目前对于神经网络模型正则化处理的研究仍然是一个重要的领域和方向,尤其是在深度学习的火爆之下,这一切十分重要,尤其是在真正实际动手训练神经网络模型的时候,解决过拟合的问题是十分重要的。但是碍于自己还没有完全学透的问题,所以只能介绍到这。
Reference
- 《机器学习》周志华
- 《深度学习》中文本
- 《深入浅出深度学习》黄安埠
- 《神经网络与深度学习》邱锡鹏
- Preventing Deep Neural Network from Overfitting
- 深度学习揭秘之防止过拟合(overfitting)
![[读书笔记]《西瓜书》第五章 神经网络 补充四](https://cdn.jsdelivr.net/gh/Ryuchen/ryuchen.github.io@master/images/machine-learning_huda146d3825fc6d502e05b38609bff098_23368_700x350_resize_q75_box.jpg)