[读书笔记]《西瓜书》第一至三章 总结
![[读书笔记]《西瓜书》第一至三章 总结](/images/machine-learning_huda146d3825fc6d502e05b38609bff098_23368_900x500_fit_q75_box.jpg)
第一至三章 总结
还记得最初的时候,刚拿到周志华老先生的《机器学习》的时候,翻看了一眼书的目录安排和周老先生在前言中的描述,深感疑惑,为啥周老先生要把线性模型纳入到机器学习基础知识,将这个部分的内容划分到与前两章节同等基础或者说是重要的程度?随着对机器学习的越来越深入,各个专业术语与名词理解的越来越深入之后,越发发现这样的安排是及其恰当与合适的,不由的感叹自己还是处在机器学习的小白阶段,还有更远的道路要往深里探寻。经过三章的西瓜书(《机器学习》)已经可以做到对机器学习管中窥豹的认识了,结合自己查找和看的资料,感觉需要对最最基础的核心知识点进行一下整理了。
这里我梳理了三个部分的内容,接下来逐一的进行阐述,会有部分内容跟前面的文章内容有重复,不过考虑到为了加深记忆和梳理脉络的清晰,所以就不考虑内容的精简性了~
机器学习
什么是机器学习?
在西瓜书中是这样来定义机器学习的主要内容的:是关于在计算机上从数据中产生“模型”(model)的算法,即“学习算法”(learning algorithm)。这个其实很好理解,即机器学习是来学习解决问题的函数的。如果用编程来类比的话,即传统编程是,先定义函数,而这个函数是已经确定性的被程序员所熟知的算法,然后给予函数相应的输入与输出,这里的先后关系是先定义了函数,然后将输入与输出与函数相匹配,但是,如果颠倒一下顺序,确定了输入与输出之后再希望找到一个函数来与之匹配该如何去做呢?这其实就是机器学习的本质,即如果确定了输入与输出的情况下来去寻找函数满足这样的一个关系。
如何衡量模型的好坏?
在知道机器学习其本质就是学到一个函数之后,那么学术界将这个函数,定义为模型(model)。OK,紧接着疑问就来了,如何评价这个模型呢?
西瓜书中林林总总的罗列了一些的对于模型性能的评估,并以此为依据来告诉读者,如何基于这些性能指标进行模型选择,然后面对模型选择给了一个总体的原则建议,即‘奥卡姆剃刀原则’。
但是,本人在读完了西瓜书这一章之后,觉得稍微有点乱,所以自己在查阅了相关内容后整理了一下,然后分成了两个部分:模型自身的评价 && 模型相互的评价
首先就是模型自身的评价,个人定义这是一个相对单一模型的概念,很多书籍和博文上来没有对此进行介绍,而是将模型间的相互评价混在一起进行了介绍,个人理解是读起来稍微会有一些犯晕,不知道应该在哪些情况下使用哪些来具体衡量,为什么使用这个评价指标来衡量。
其实,我觉得将两者稍微划分开一下,可能更能很好的理解一下。
模型自身的评价
当我们为了将数据集进行一个很好的建模的时候,我们需要对我们的预期模型输出进行一个合理的预估,这就是对模型自身的评价的衡量,比如:当我们进行一个线性回归建模的时候,我们可能会建立一个评价标准,为模型的输出与真实值之间的平方差之和。这里的这个平方差之和就是对于当前这个模型的评价,怎么样,是不是很好理解?
当然有许多其他的对于模型的评价手段,各类书籍中也有介绍,但是要明白一点我们需要对模型的输出有个预期的评估,而通过评估来选择合适的评价标准。
模型相互的评价
当我们有了一个模型评价指标时,例如上面说的平方差之和,那么,我们想改进这个误差,该怎么做呢?产生这个疑问所对应的就是模型相互间的评价产生的由来,即单一的看模型的自身评价结果,可能是毫无意义的,因为这并不能帮助我们将模型的效果进行改良,所以我们需要引入模型间的相互评价来进行抉择。
当我们依据模型的评价指标进行模型中的参数修改时,这里得到的就是第二个模型了,而此时第二个模型在评价指标上的输出,对比之前模型的输出,则帮助我们进行选择哪一个模型跟为优秀。
个人觉得这里可以做一个很好地类比理解:模型自身的评价可以输出变成一个集合,而相互评价即从这些中选择最优的。
个人理解:这也是损失函数的由来,即我们定义了一个关于模型间相互评价的函数,这个函数能够帮助我们很好地进行模型择优
PS: 我觉得这也是很多科研论文作弊最严重的地方,因为目前看来模型间的相互评价并没有统一的规范的标准(个人见解)
基本任务
通过西瓜书前三章的学习,可以洞察一下经典机器学习的最初始的面貌,经典机器学习主要研究两个目标:回归分析(Regression Analysis)和分类分析(Classification Analysis),而目前机器学习则在此基础上增加了一个研究的目标:生成分析(Generation Analysis)。现在的机器学习发展都是建立在如何生成,或者更好的生成的研究方向上,不过这个部分需要自己再深入的掌握才能阐述明白,因此还是回到前面两个基础研究目标上来阐述。
这两个作为经典机器学习所解决的两大问题,其实很好理解,我相信找到当今任何一本机器学习的科普书籍都一定是从这两大类别来进行梳理内容知识的,而目前的任何研究问题都是建立在这之上的内容。
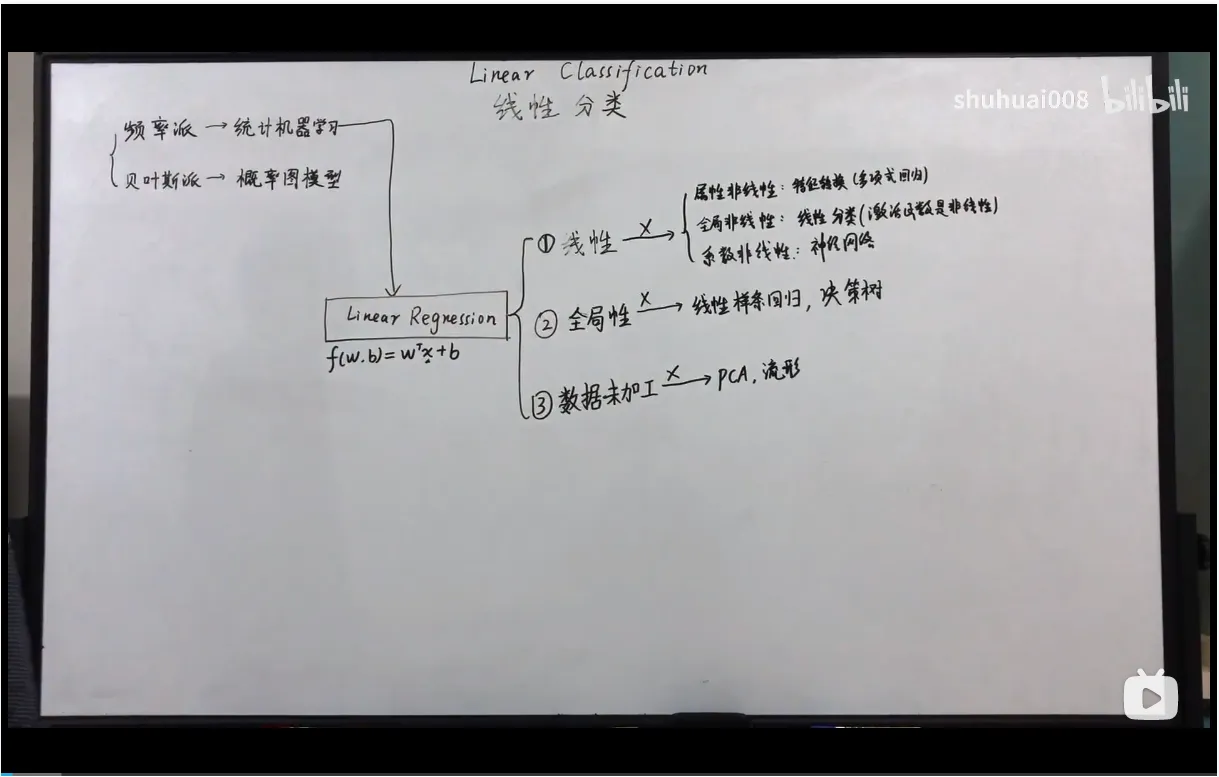
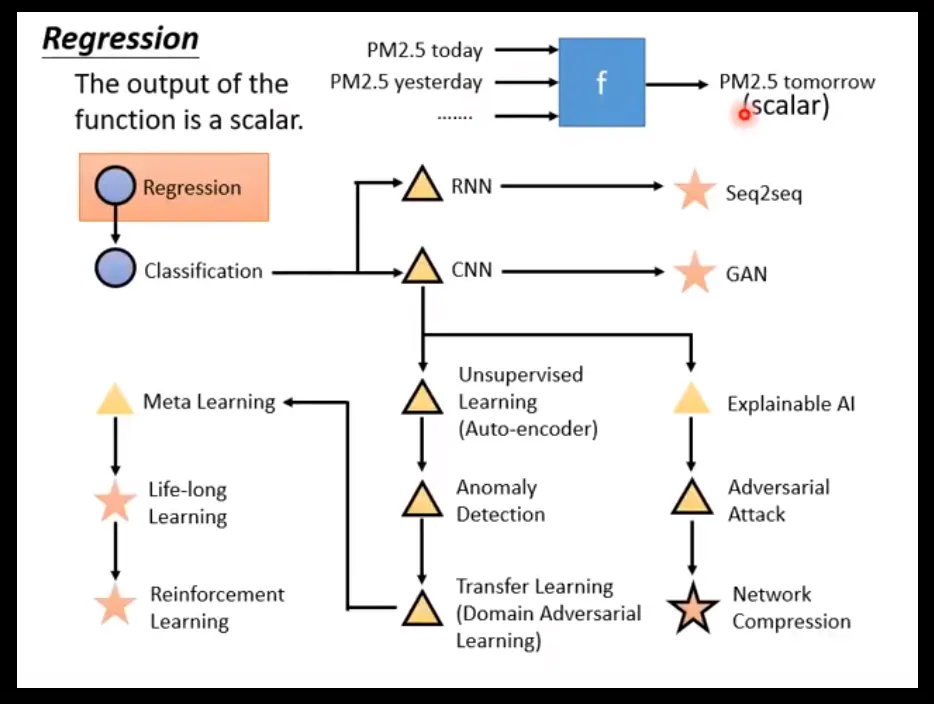
首先Po出B站大佬shuhuai008的视频截图和台大李宏毅老师的2020年机器学习教学视频的截图
回归分析
首先就是回归分析,很多书都是把这个内容当做十分简单的内容来进行介绍的,很快速的就带过了,很多书本都还是默认大家都完全掌握了回归分析的内容。但是经过我搜寻了一些资料之后,发现并没有这么简单。
个人觉得:回归分析,可以看做机器学习中大部分的“起源”来看待。
这里其实上面两个图展示也比较清楚了,相关视频地址我会放到文末,但是这里简要的阐述一下自己的理解。
首先就是回归分析是来自于统计机器学习学派的,其本生是建立在四个基本假设的前提下的,这四个基本假设上一篇博文中有说明。而其他的模型则是在此基础上,逐一打破其四个基本假设的前提下,进行的推广和拓展(这里是引用了shuhuai008大佬的见解)。
分类分析
然后就是分类分析,这个通过上面的台大李宏毅教授的PPT可以看得出来,主要是可以看做是从回归分析中推广得来的,这里需要结合上面模型评价的内容来看。
通常情况下,分类的准确与否都是通过大家熟知的混淆矩阵来进行评价的,但是这样的评价显然对于在模型集合中求解最优模型不是很方便,因为我们在进行搜寻的时候是一个无目标无方向的,我们无法知道通过损失函数对模型参数进行调整的时候会引发结果产生多大的变化。
这种情况下,前人的研究给出了诸多方案,其中一种方式就是类比了激活函数的形式,建立一个可导可微的方程,而这个方程能够具备在0点坡度极陡,而在两端坡度平稳的性质。
对比总结
在shuhuai008大佬进行总结的内容中,可以看到,当线性模型的四大假设前提逐一打破的时候产生了拓展了新的模型。
首先就是基本线性回归的四个假设前提中,属性之间线性相关的假设,即最初假设:因变量和自变量之间关系存在线性的关系且具有可加性。当打破这个假设前提时,则构成了我们熟知的多项式回归。
其次在打破属性非线性的情况下,继续打破全局线性的假设,即最初假设:当其他自变量不变时,因变量的期望值可以通过任一自变量的一条直线函数得到。当我们不以拟合直线为目标时,则构成了我们熟知的线性分类。
然后是在前两者的基础之上,继续打破系数线性的假设,即最初假设:该线的斜率不取决于其他因变量的值,不同自变量对因变量期望值的影响是累加的。当不同自变量对因变量产生了不同影响,呈现非线性的关系时,我们则可以形成感知机模型。
此外在打破线性假设的基础上,如果我们不期望样本集在全体数据上能够呈现有效的拟合时,则可以将样本集进行分段处理,于是再此基础上,我们形成了决策树模型。
另外就是对于样本数据本身的属性是呈现的相互独立性假设基础上,即我们传统线性模型是假设样本数据的特征是在欧式空间中的形态,但是当这个严格的条件不复存在时,如何进行特征选取和非欧空间的线性拟合诞生了相应的模型。
总结一下,当这所有的机器学习的模型,要学起还是要从最根本的线性回归开始~
下面是shuhuai008大佬的视频直达链接和台大李宏毅老师的B站视频搬运
以上内容也可以到我的 Github 去查看(附了相应实现代码哟) Machine-Learning-Notes
![[读书笔记]《西瓜书》第三章 线性模型 补充](https://cdn.jsdelivr.net/gh/Ryuchen/ryuchen.github.io@master/images/machine-learning_huda146d3825fc6d502e05b38609bff098_23368_700x350_resize_q75_box.jpg)