[读书笔记]《西瓜书》第二章 模型评估与选择 补充
![[读书笔记]《西瓜书》第二章 模型评估与选择 补充](/images/machine-learning_huda146d3825fc6d502e05b38609bff098_23368_900x500_fit_q75_box.jpg)
第二章 模型评估与选择 补充
过拟合
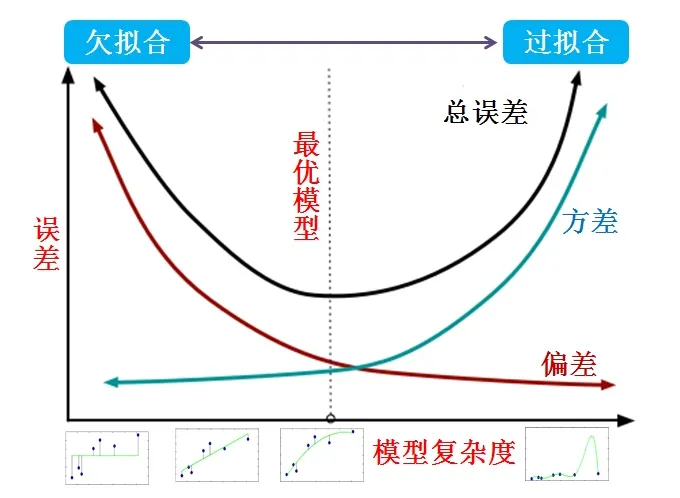
什么是过拟合?
欠拟合像是差学生中“不会读书”的那种,过拟合则像是好学生中“死记硬背”的那种
- 过拟合指的是训练误差和测试误差之间的差距太大
- 模型的复杂度过高,于是在训练集上表现得很好,但在测试集上却表现很差
- 同欠拟合一样,没有理解数据背后的规律
为什么会出现?
-
训练数据不足
根本性原因
- 数量上
- 类型上
-
训练数据噪声干扰过大
-
模型过于复杂
- 现在的实际问题中,通常会出现的就是因为模型选取的过于复杂
如何解决
数据增强(Data Augmentation)
- 解决过拟合的根本性方法
- CNN图像领域用的较多
正则化(Regularization)
- 选取合适的模型(奥卡姆剃刀原则)
- 本质上就是对学习算法进行了修改
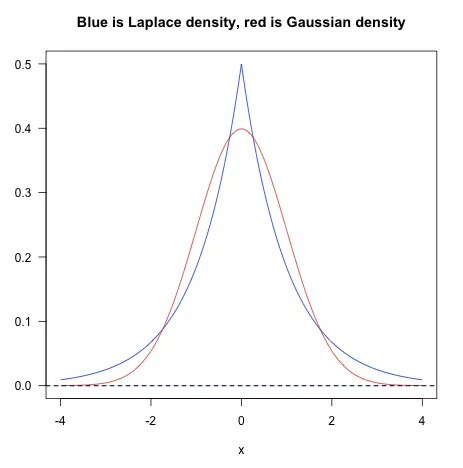
L1正则化
- 在原损失函数后面加上全部权重的绝对值之和,再乘以系数
- $C=C_0 + \frac{\lambda}{n} \sum_{i}|w_i|$
- L1的稀疏性更好的能够为我们选取特征
L2正则化
- 在原损失函数后面加上全部权重的平方和,再乘以系数
- $C = C_0 + \frac{\lambda}{2n}\sum_{i}{w}_{i}^2$
- L2的权重衰减特性使得其对于outlier更敏感
实际应用过程中,L1几乎没有比L2表现好的时候,优先使用L2是比较好的选择。
Bagging
- 通过有放回的随机采样实现了对样本集中噪声的影响的有效的降低
- 集成学习Bagging使模型更加的稳定,其作用是因为降低了模型的方差,对过拟合有一定的作用
随机失活(Dropout)
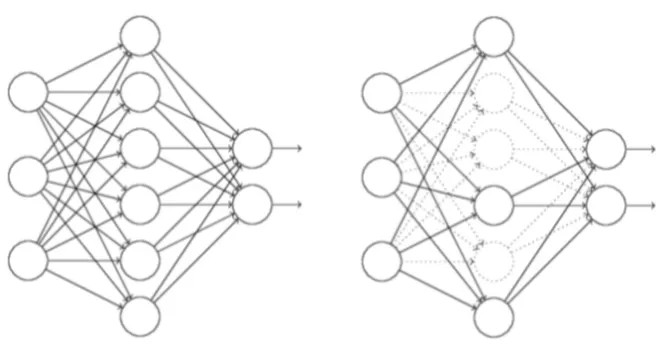
- 训练神经网络时的一种技巧(trike),相当于在隐藏单元中增加了噪声
- 指的是在训练过程中每次按一定的概率(比如50%)随机地“删除”一部分隐藏单元(神经元)
- 所谓的“删除”不是真正意义上的删除,其实就是将该部分神经元的激活函数设为0(激活函数的输出为0),让这些神经元不计算而已。
提前终止(Early Stopping)
- 最经典的就是在使用梯度下降的迭代算法进行模型训练时,通过截断迭代次数,来对模型达到收敛之前进行停止迭代
- 理论上可能的局部极小值数量随参数的数量呈指数增长, 到达某个精确的最小值是不良泛化的一个来源. 实践表明, 追求细粒度极小值具有较高的泛化误差。
逐层归一化(Batch Normalization)
- 给每层的输出都做一次归一化(网络上相当于加了一个线性变换层), 使得下一层的输入接近高斯分布
- 相当于下一层的w训练时避免了其输入以偏概全, 因而泛化效果非常好
模型选择
精度(accuracy)
模型精度的主要测量来自于估计给定模型的测试误差。因此,模型选择的精度提高目标是减少估计的测试误差。需要注意的是,通常提高模型性能,模型精度可以提高,但是提高的幅度递减 (diminishing return)。鉴于此,选择模型并不总是要它最精准。有时还必须考虑其他重要因素,包括可解释,高效,可扩展和简单。
可解释(interpretability)
通常,给定的一个应用程序,你可能需要折中一下模型精度和模型可解释性。人工神经网络 (ANN, aritificial neural network),支持向量机 (SVM, suppport vector machine) 和一些集合方法 (ensemble methods) 可以用于创建非常精确的预测模型,但是对非专业人士就是个黑盒子。
高效(efficiency)
当预测性能是首要目标时并且不需要解释模型如何工作和进行预测,可以优选黑盒算法。然而,在某些情况下,模型可解释性是首选,有时甚至是法律强制的。比如在金融业,假设机器学习算法用于接受或拒绝个人的信用卡应用程序。如果申请人被拒绝并决定提出投诉或采取法律行动,金融机构将需要解释该决定是如何做出的。虽然这对于 ANN 或 SVM 系统几乎是不可能的,但对于基于决策树 (decision tree) 的算法来说是相对直接的。
可拓展(scalability)
在训练,测试,处理和预测速度方面,一些算法和模型类型需要更多的时间,并且需要比其他算法和存储器更大的计算能力和内存。在一些应用中,速度和可扩展性是关键因素,特别是在任何广泛使用的接近实时的应用 (电子商务站点) 中,给了一个新数据,模型就需要快速更新,并且在大数据上预测或分类。
简单(simplicity)
一个好的方法是从简单模型开始,然后根据需要才增加模型复杂性。 一般来说,简单应该是首选,除非复杂模型可以大幅度提高精度。
以上内容也可以到我的 Github 去查看(附了相应实现代码哟) Machine-Learning-Notes
![[读书笔记]《西瓜书》第二章 模型评估与选择](https://cdn.jsdelivr.net/gh/Ryuchen/ryuchen.github.io@master/images/machine-learning_huda146d3825fc6d502e05b38609bff098_23368_700x350_resize_q75_box.jpg)
{kind=link}