[读书笔记]《西瓜书》第一章 绪论
![[读书笔记]《西瓜书》第一章 绪论](/images/machine-learning_huda146d3825fc6d502e05b38609bff098_23368_900x500_fit_q75_box.jpg)
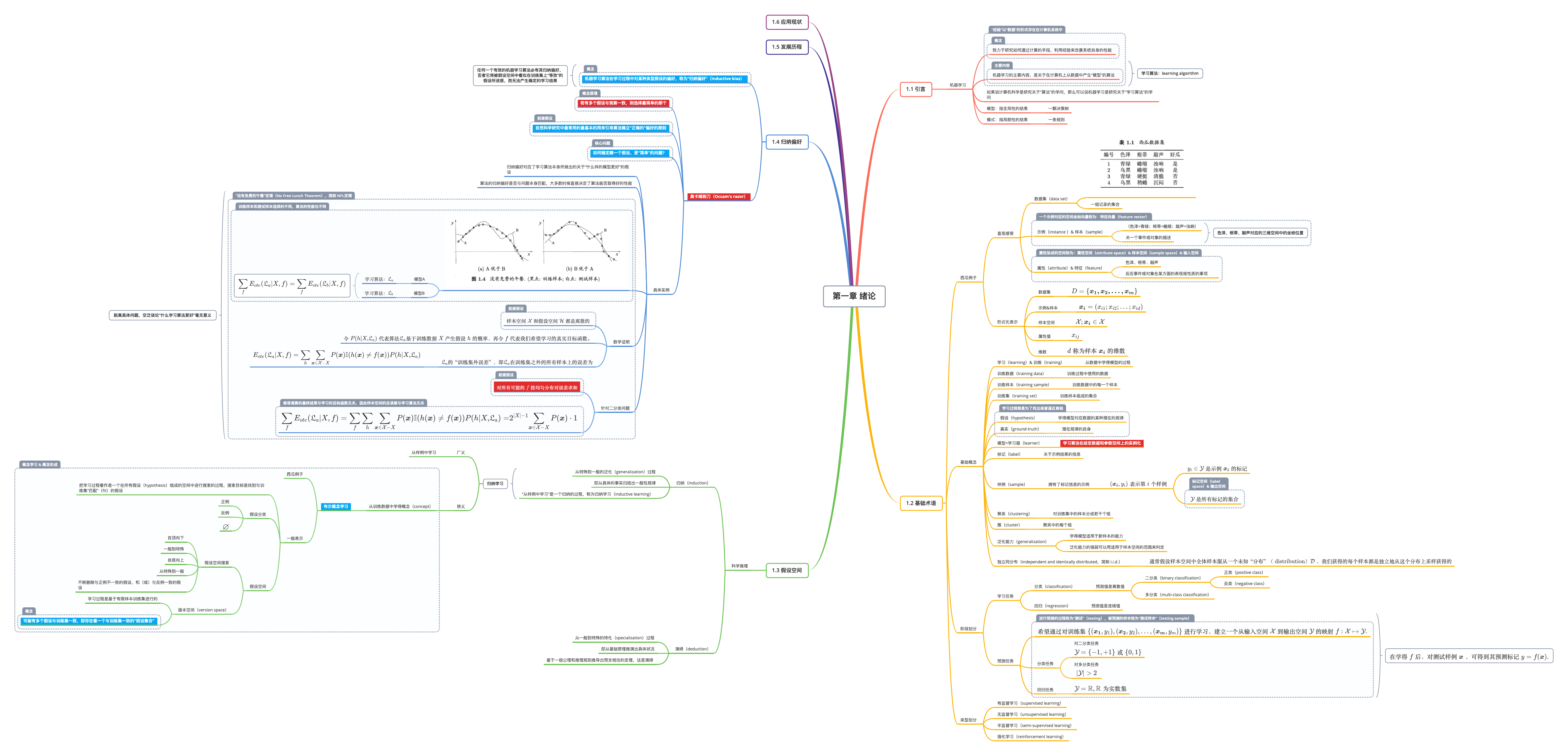
第一章 绪论
1.1 引言
机器学习(Machine Learning)
人们可以利用经验对很多事物做出预判,而对经验的利用除了靠我们人类自身完成之外,计算机能帮忙吗?
机器学习的定义
经验化:
机器学习正式这样一门科学,它致力于研究如何通过计算的手段,利用经验来改善系统自身的性能
形式化:
假设用P来评估计算机程序在某任务类T上的性能,若一个程序通过利用经验E在T中任务上获得了性能改善,则我们就说关于T和P,该程序对E进行了学习
机器学习的主要内容
机器学习的主要内容,是关于在计算机上从数据中产生“模型”(model)的算法,即“学习算法”(learning algorithm)
如果说计算机科学是研究关于”算法“的学问,那么类似的,可以说机器学习是研究关于”学习算法“的学问
模型
指全局性的结果
eg: 一颗决策树
模式
指局部性的结果
eg: 一条规则
1.2 基础术语
西瓜例子直观感受
数据集(data set)
一组记录的集合
- (色泽=青绿;根蒂=蜷缩;敲声=浊响), (色泽=乌黑;根蒂=稍蜷;敲声=浊响), (色泽=青绿;根蒂=硬挺;敲声=清脆), …
示例(instance )& 样本(sample)
关一个事件或对象的描述
- (色泽=青绿;根蒂=蜷缩;敲声=浊响)
属性(attribute)& 特征(feature)
反应事件或对象在某方面的表现或性质的事项
- 色泽、根蒂、敲声
形式化定义与表示
数据集
- $D=\left\{ \boldsymbol{x_1,x_2,…,x_m} \right\}$
示例&样本
- $\boldsymbol{x_i}=\left(x_{i1};x_{i2};…;x_{id}\right)$
样本空间
- $\mathcal{X};\boldsymbol{x_i} \in \mathcal{X}$
属性值
- $x_{ij}$
维数
- $d$ 称为样本 $\boldsymbol{x_i}$ 的维数
其他概念
学习(learning)& 训练(training)
从数据中学得模型的过程
训练数据(training data)
训练过程中使用的数据
训练样本(training sample)
训练数据中的每一个样本
训练集(training set)
训练样本组成的集合
假设(hypothesis)
学得模型对应数据的某种潜在的规律
真实(ground-truth)
潜在规律的自身
模型=学习器(learner)
学习算法在给定数据和参数空间上的实例化
标记(label)
关于示例结果的信息
样例(sample)
拥有了标记信息的示例
- $(\boldsymbol{x_i}, y_i)$ 表示第 $i$ 个样例
- $y_i\in{\mathcal{Y}}$ 是示例 $\boldsymbol{x_i}$ 的标记
- $\mathcal{Y}$ 是所有标记的集合
- 标记空间 & 输出空间
聚类(clustering)
对训练集中的样本分成若干个组
簇(cluster)
聚类中的每个组
泛化能力(generalization)
学得模型适用于新样本的能力
- 泛化能力的强弱可以用适用于样本空间的范围来判定
独立同分布(independent and identically distributed,简称 i.i.d.)
通常假设样本空间中全体样本服从一个未知“分布”(distribution) $\mathcal{D}$ ,我们获得的每个样本都是独立地从这个分布上采样获得的
阶段划分
学习任务
分类(classification)
预测值是离散值
-
二分类(binary classification)
- 正类(positive class)
- 反类(negative class)
- ···
-
多分类(multi-class classification)
- 聚类 (clustering)
- ···
回归(regression)
预测值是连续值
预测任务
希望通过对训练集 $\left\{(\boldsymbol{x_1},y_1), (\boldsymbol{x_2},y_2),…,(\boldsymbol{x_m},y_m)\right\}$ 进行学习,建立一个从输入空间 $\mathcal{X}$ 到输出空间 $\mathcal{Y}$ 的映射 $f:\mathcal{X}\mapsto\mathcal{Y}$ .进行预测的过程称为“测试”(testing),被预测的样本称为“测试样本”(testing sample)
分类任务
- 对二分类任务: $\mathcal{Y}=\left\{-1,+1\right\}或\left\{0,1\right\}$
- 对多分类任务: $\left | \mathcal{Y} \right | >2$
回归任务
- $\mathcal{Y}=\mathbb{R},\mathbb{R}为实数集$
在学得 $f$ 后,对测试样例 $\boldsymbol{x}$ ,可得到其预测标记 ${y=f\left(\boldsymbol{x}\right)}$ .
类型划分
有监督学习(supervised learning)
它从有标记的训练数据中推导出预测函数。有标记的训练数据是指每个训练实例都包括输入和期望的输出。一句话:给定数据,预测标签。
无监督学习(unsupervised learning)
它从无标记的训练数据中推断结论。最典型的无监督学习就是聚类分析,它可以在探索性数据分析阶段用于发现隐藏的模式或者对数据进行分组。一句话:给定数据,寻找隐藏的结构。
半监督学习(semi-supervised learning)
对于半监督学习,其训练数据的一部分是有标签的,另一部分没有标签,而没标签数据的数量常常远远大于有标签数据数量(这也是符合现实情况的)。
强化学习(reinforcement learning)
它关注的是软件代理如何在一个环境中采取行动以便最大化某种累积的回报。一句话:给定数据,学习如何选择一系列行动,以最大化长期收益。
1.3 假设空间
科学推理
归纳(induction)
- 从特殊到一般的泛化(generalization)过程
- 即从具体的事实归结出一般性规律
- “从样例中学习”是一个归纳的过程,称为归纳学习(inductive learning)
演绎(deduction)
- 从一般到特殊的特化(specialization)过程
- 即从基础原理推演出具体状况
- 基于一组公理和推理规则推导出预支相洽的定理,这是演绎
1.4 归纳偏好
机器学习算法在学习过程中对某种类型假设的偏好,称为“归纳偏好”(inductive bias)
奥卡姆剃刀(Occam’s razor)
若有多个假设与观察一致,则选择最简单的那个
自然科学研究中最常用的最基本的用来引导算法确立“正确的”偏好的原则
如何确定哪一个假设,更“简单”的问题?
归纳偏好对应了学习算法本身所做出的关于“什么样的模型更好”的假设
算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法能否取得好的性能
具体如下
定义模型A的学习算法:$\mathfrak{L}_a$
定义模型B的学习算法:$\mathfrak{L}_b$
并且
数学证明
样本空间 $\mathcal{X}$ 和假设空间 $\mathcal{H}$ 都是离散的
令 $P\left(h|X,\mathfrak{L}_a\right)$ 代表算法 $\mathfrak{L}_a$ 基于训练数据 $X$ 产生假设 $h$ 的概率,再令 $f$ 代表我们希望学习的真实目标函数。
$\mathfrak{L}_a$ 的“训练集外误差”,即 $\mathfrak{L}_a$ 在训练集之外的所有样本上的误差为
针对二分类问题
对所有可能的 $f$ 按均匀分布对误差求和
推导演算的最终结果与学习的目标函数无关,因此样本空间的总误差与学习算法无关
脱离具体问题,空泛谈论“什么学习算法更好”毫无意义
1.5 发展历程
1.6 应用现状
以上内容也可以到我的 Github 去查看(附了相应实现代码哟) Machine-Learning-Notes
{kind=link}